0、概述
这段时间主要学习了kaggle网站上的“机器学习”的部分。之前很长一段时间都是在学习
理论,没有机会实践,Kaggle是个不错的平台,有很多使用的难题等待着全世界聪敏的头脑
去解决。通过本篇的学习,很好的将理论知识用到了实践当中,比如之前学习到的绘制模型在
样本集和测试集上的准确率,防止模型过拟合和欠拟合,选择最优的点。还有之前不明白交叉
验证的作用,以及实际效果。网址:https://www.kaggle.com/learn/machine-learning
1、思维导图
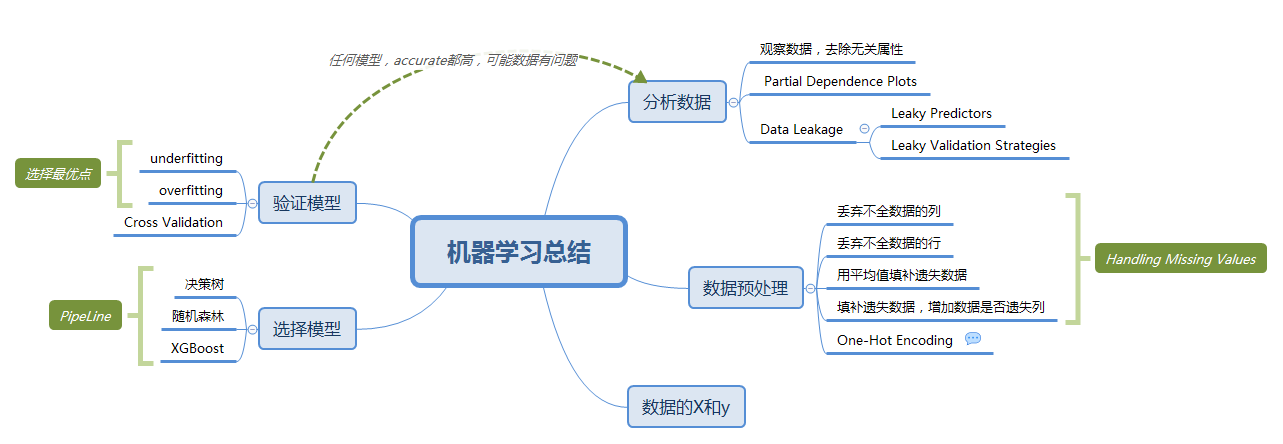
2、步骤
2.1、分析数据
1 | ############## 观察数据 ############## |

2.2、数据处理
1 | ############## 检查数据是否有空项 ############## |
2.3、选择模型
1 | ############## 决策树回归 ############## |
2.4、验证模型
1 | ############## 模型在测试集上的误差 ############## |
3、总结
机器学习是一种数据处理的科学,采用科学的分析方式调整模型的参数,试验的数据,达到提高识别率的目的。

