0、概述
本阶段完成了关于数据可视化的学习,这部分的学习为我打开了一扇通往新世界的大门。
一个人如果能再某个领域成为专家就已经是一件很了不起的事情了,对于MachineLearner来说,将会面对不同领域的问题,需要具备不同的DomainKnowledge是一件几乎不可能的事情,可能我们通过几周或者甚至几天的学习,对问题领域有个大概的了解,但是对不同的Feature之间的关系,影响可能就无法知晓了,当然我们可以通过咨询相应领域的专家,不过这实际上也是一件相当不易的事情。
数据可视化就想武器中的瑞士军刀,它将数据以图表的形式展现在MachineLearner的面前,通过观察图表,我们可以知道数据与数据之间的联系,可以连接到数据的走上,范围,概率分布等。通过这些,我们可以方便的挑选适合我们模型的Features。
1、思维导图
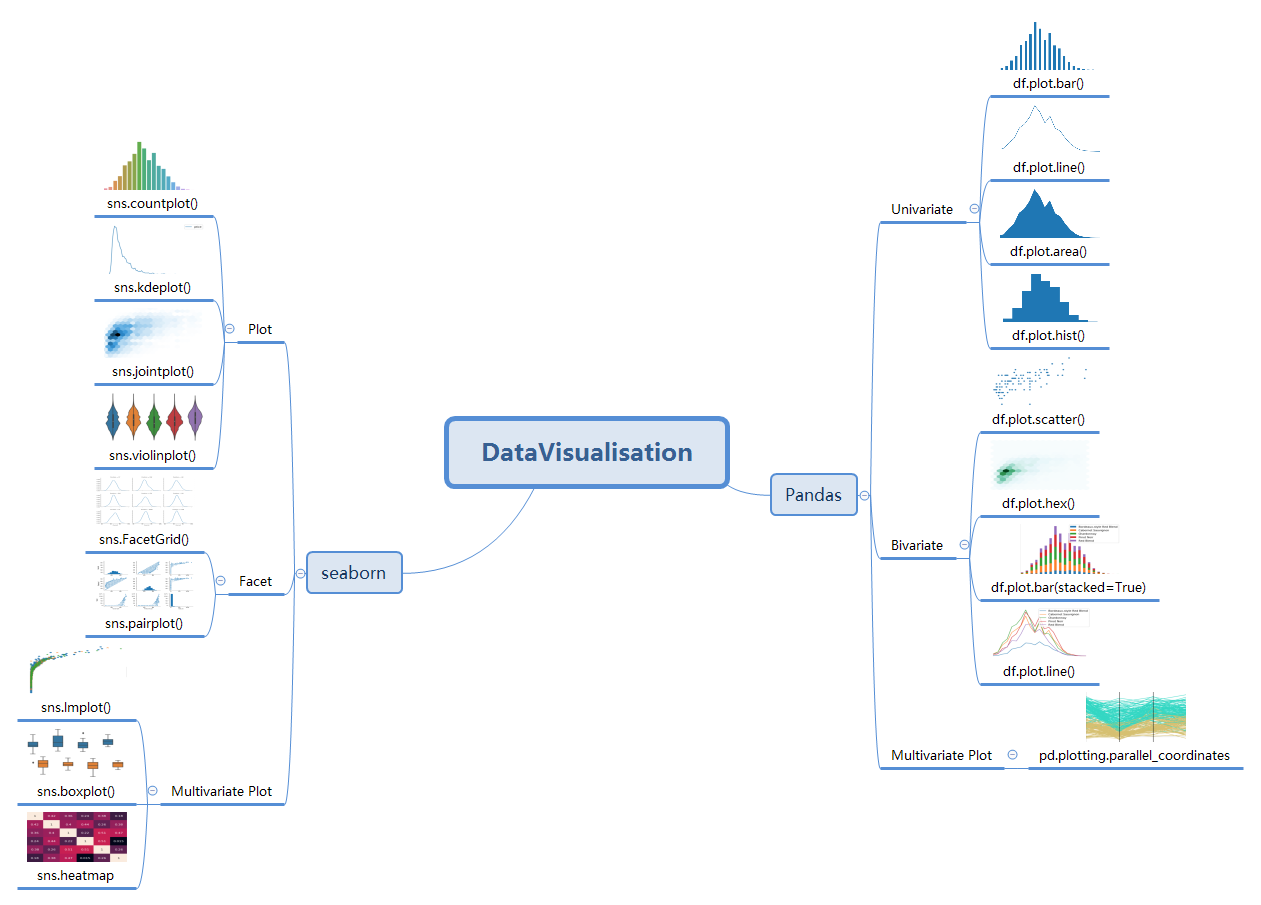
2、使用方法
2.1、Univariate plotting with pandas
1 | import pandas as pd |
2.2、Bivariate plotting with pandas
1 | import pandas as pd |
2.3、Multivariate plotting with pandas
1 | import pandas as pd |
2.4、Plotting with seaborn
1 | import pandas as pd |
2.5、Faceting with seaborn
1 | # Facet Grid |
2.6、Multivariate plotting with seaborn
1 | # Multivariate Scatter Plot |
3、总结
通过这一阶段的学习,掌握了主流的python库pandas,seaborn的绘图方法,之前学习的matplotlib的知识也在这段时间稍微复习了一下,希望在今后的实践中好好运用数据可视化这部分的知识。并且帮助评价训练出来的模型。

